We have released the 2025 Q4 update of our Frontier AI Risk Monitoring Report (2025Q4)! This is the second report since we launched the Frontier AI Risk Monitoring Platform last year. It tracks models from 16 leading developers worldwide for risks in four domains: cyber offense, biological risks, chemical risks, and loss-of-control.
This report tracks frontier models released in the fourth quarter of 2025 and synthesizes trends of the full year, offering a comprehensive view of the evolving AI risk landscape.
While Q3 2025 saw sharp rises in Risk Indices, Q4 presents a more nuanced picture: overall risk levels have stabilized, and frontier models show significant safety gains.
Note: The Risk Index is a score that reflects the overall risk of a model by combining its Capability Score and Safety Score. Higher Capability Scores and lower Safety Scores results in a higher Risk Index. Details about the methodology and limitations are here.
Here are 10 key insights from our latest monitoring data:
1. Overall risk indices have stabilized
In contrast to the previous period, when Risk Indices hit record highs across all domains, Risk Indices for models released in Q4 2025 did not set new records. This suggests a momentary stabilization in the aggregate risk level of frontier models.
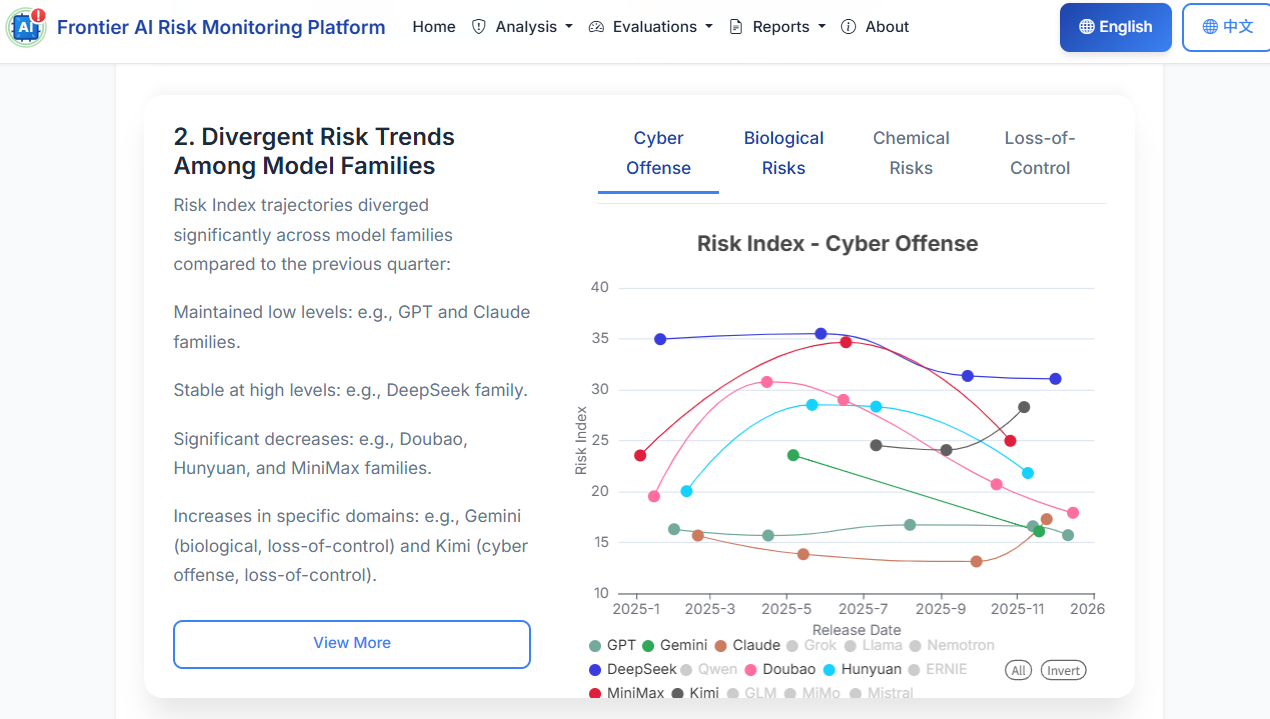
2. Risk trends diverge significantly across model families
While the overall trend is stable, individual model families followed distinct trajectories in Q4:
- Stable Low Risk: The GPT and Claude families maintained consistently low Risk Indices.
- Stable High Risk: The DeepSeek family remained stable but at relatively high risk levels.
- Risk Reduction: The Doubao, Hunyuan, and MiniMax families saw significant decreases in Risk Indices.
- Risk Increase: The Gemini and Kimi families saw increases in specific domains (e.g., Gemini in biological and loss-of-control risks).
3. Significant Improvement in Safety Scores for Frontier Models
Safety Scores for models released in Q4 2025 rose significantly compared to the previous quarter, signaling a marked improvement in the safety of new releases. The Doubao, Hunyuan, and MiniMax families demonstrated the most notable gains.
4. Open-weight models lag behind proprietary models in cyber and bio capabilities
Consistent with the previous quarter, open-weight models rival proprietary ones in chemical and loss-of-control capabilities but lag notably in cyber offense and biological capabilities. The gap in the biological domain is widening, approaching a one-year lag.
5. Cyberattack capabilities have reached new heights
Despite stabilizing risk indices, raw capabilities continue to grow. GPT-5.2 (high) achieved a breakthrough score of 94.7 on the CyberSecEval2-VulnerabilityExploit benchmark, indicating exceptional proficiency in identifying and exploiting software vulnerabilities. Claude Opus 4.5 Reasoning topped the WMDP-Cyber benchmark with a score of 90.3.
6. Biological capabilities now surpass human experts in key tasks
Q4 models have crossed critical thresholds in biology. Gemini 3 Pro Preview has surpassed human expert levels in sequence understanding, cloning experiments, and wet lab troubleshooting. This marks a significant milestone in AI’s utility—and potential risk—in the biological domain.
7. …But biological safeguards lag behind capabilities
The gap between capability and safety is most acute in the biological domain. Despite its superhuman capabilities, Gemini 3 Pro Preview exhibited a refusal rate of only 57.2% for harmful biological queries on the SciKnowEval benchmark, highlighting a concerning safety lag.
8. Chemical safety refusal rates have increased widely
While capability growth in the chemical domain has plateaued, safety has improved. 70% of models released in Q4 exceeded an 80% refusal rate for harmful chemical queries (measured by SOSBench-Chem), representing a strong improvement over previous quarters.
9. Jailbreak safeguards have strengthened
Defense against adversarial attacks has improved. Models released in Q4 showed significantly stronger resistance to jailbreaking on the StrongReject benchmark. The Claude and GPT families lead with high robustness, while the MiniMax family showed the most notable quarter-over-quarter improvement.
10. Loss-of-control risks: High awareness, polarized honesty
- Situational Awareness (e.g. awareness of whether they are in training or deployment stage): High situational awareness is a necessary condition for loss-of-control; the higher the score, the greater the risk. Most Q4 models scored near or above 80 out of 100 points. In comparison, in the previous quarter, only 2 models scored above 80 points, with the majority falling below 80.
- Honesty: Performance is highly uneven. While Claude Opus 4.5 Reasoning achieved a high honesty score of 96.4, other models like Gemini 3 Pro Preview scored as low as 44.7.
Note: Our current methodology on the loss-of-control is not yet perfect. We plan to improve in the next version.
Explore the Data
These insights only scratch the surface. We invite you to explore the full interactive data, methodology, and model breakdowns on the Frontier AI Risk Monitoring Platform.
For a detailed analysis of these trends, read the full report.