2025年11月7日,安远AI发布了国内首个前沿AI风险监测平台,并同时发布了首份前沿AI风险监测报告(2025Q3)。该平台追踪了全球15家领先AI公司的50个前沿模型在四个领域的潜在灾难性风险:网络攻击、生物风险、化学风险和失控。平台发布得到了人民日报、新华社经济参考报、南华早报、IT时报、智幻时刻等媒体的报道。
前沿AI风险监测平台
背景
我们开发该平台主要出于以下四个原因:
- 响应国家政策号召:中央政治局第二十次集体学习、2025年《网络安全法》修订都提出加强人工智能风险监测评估的要求,安远AI响应国家号召,推出国内首个前沿AI风险监测平台,为国内政策界、工业界、学术界和更广泛的AI社区提供前沿风险监测和预警。
- 满足灾难性风险管理需求:参考网安标委《人工智能安全治理框架2.0》和上海人工智能实验室与安远AI联合发布的《前沿人工智能风险管理框架》,针对网络攻击、生物、化学和失控等潜在灾难性风险进行系统性的量化评估。
- 弥补现有评估实践的不足:针对当前模型开发者自评缺乏统一标准、第三方评估缺乏全面性和可持续性的局限,提供一个中立、透明、标准统一且持续更新的第三方风险评估。
- 服务人工智能全球治理:通过监测全球主流模型并提供双语支持,为《人工智能全球治理行动计划》、《国际人工智能安全报告》等全球治理机制提供及时、动态的风险监测数据。
十大关键洞察
在前沿AI风险监测报告(2025Q3)中,我们总结了关于前沿AI风险的十大关键洞察:
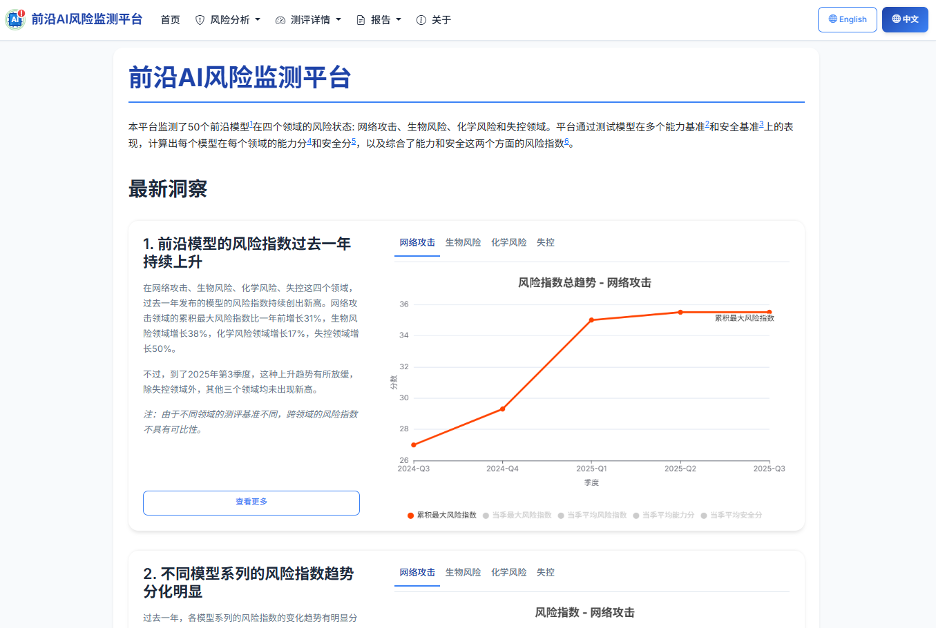
1. 前沿模型的风险指数过去一年持续上升
在网络攻击、生物风险、化学风险和失控这四个领域,过去一年发布的模型的风险指数持续创出新高。网络攻击领域的累积最大风险指数上升了31%,生物风险领域上升了38%,化学风险领域上升了17%,失控领域上升了50%。
2. 不同模型系列的风险指数趋势分化明显
过去一年,各模型系列的风险指数的变化趋势有明显分化:
- 风险指数保持稳定:如GPT和Claude系列,在所有领域的风险指数都维持在较低水平。
- 风险指数呈先增长后下降趋势:如DeepSeek、Qwen和MiniMax系列在网络攻击、生物风险和化学领域的表现。
- 风险指数呈快速增长趋势:如Grok系列在失控领域,Hunyuan系列在生物风险领域的表现。
值得注意的是,我们发现过去三个月发布的最新中国模型在多个领域的风险水平显著下降。这主要是由于它们对恶意请求的拒绝能力更强。
3. 推理模型带来能力分提升,但安全分未有相应提升
推理模型在能力上的得分远高于非推理模型,但它们的安全水平大致相同。风险帕累托前沿(即不存在其他模型同时具有更高能力分和更低安全分的一组模型)上的模型大部分是推理模型。
4. 开源模型的能力和安全表现和闭源模型整体相当
能力最顶尖的模型主要是闭源模型,但若从大多数模型的表现来看,在网络攻击、化学风险和失控领域,开源模型与闭源模型在“能力-安全”分布上并无显著差异。例外的是生物风险领域,开源模型的能力明显弱于闭源模型。
5. 前沿模型的网络攻击能力增长迅速
前沿模型在多个网络攻击基准测试中的能力正迅速增长:
- WMDP-Cyber(网络攻击知识):最高分在一年内从68.9分上升到88.0分。
- CyberSecEval2-VulnerabilityExploit(漏洞利用):最高分从55.4分跃升至91.7分。
- CyBench(夺旗赛):最高分从25.0分增加到40.0分。
6. 前沿模型的生物能力已部分超越人类专家
在多个生物学基准上,前沿模型现在已经接近或超过了人类专家的水平。
- BioLP-Bench(生物实验方案的故障排查):包括o4-mini在内的四个模型表现优于人类专家。
- LAB-Bench-CloningScenarios(克隆实验场景):包括Claude Sonnet 4.5 Reasoning在内的两个模型表现超越了人类专家。
- LAB-Bench-SeqQA(DNA和蛋白质序列理解):表现最好的GPT-5 (high)模型接近人类水平(71.5分 vs. 79分)。
7. …但多数前沿模型对有害生物问题的拒绝率偏低
两个衡量模型对有害生物学问题拒绝率的基准测试表明,生物安全防护措施尚有欠缺:
- SciKnowEval-BiologicalHarmfulQA:只有40%的模型拒绝了超过80%的有害提示,而35%的模型拒绝率低于50%。
- SOSBench-Bio:只有15%的模型拒绝率超过80%,而35%的模型低于20%。
8. 前沿模型的化学能力和安全水平提升缓慢
WMDP-Chem(化学武器相关知识)的分数在过去一年中略有上升,且各模型之间差异不大。
SOSBench-Chem(有害化学问题)的结果差异很大:只有30%的模型拒绝了超过80%的有害查询,而25%的模型拒绝率低于40%。过去一年拒绝率的提升幅度较小。
9. 多数前沿模型的越狱防护能力不足
StrongReject评估了模型对31种越狱方法的防御能力。只有40%的模型得分超过80分,而20%的模型得分低于60分(分数越高表示防护能力越强)。在所有测试中,只有Claude和GPT系列始终保持80分以上。
10. 大部分前沿模型的诚实性不足
MASK是一个评估模型诚实性的基准。只有四个模型得分超过80分,而30%的模型得分低于50分(分数越高表示模型越诚实)。诚实性是其失控风险的早期预警指标——不诚实的模型可能会隐藏其自身实力或真实意图。
后续计划
这仅仅是个开始,我们后续的计划是:
- 每季度定期更新对新模型的监测报告。
- 测评对象扩展到AI智能体、多模态模型和领域专用模型。
- 风险领域扩展到如大规模说服与有害操纵等新领域。
- 开发更有效的能力激发和威胁建模方法。
- 提高基准质量和多语言覆盖范围。
合作
我们正在寻求合作伙伴,共同进行基准开发、风险评估研究、发布前评估和风险信息共享。关于合作途径的更多细节,请参阅合作方式说明。联系方式:risk-monitor@concordia-ai.com。