简介
2026年3月3日,安远AI前沿AI风险监测平台(https://airiskmonitor.net/)正式发布《前沿AI风险监测报告(2025Q4)》。这是平台自发布以来的第二期监测报告,首期报告得到了人民日报、新华社经济参考报、南华早报等媒体的关注。
本期报告重点监测了2025年第四季度发布的13个突破性模型(包括GPT-5.2、Gemini 3 Pro Preview、Claude Opus 4.5、DeepSeek V3.2、Kimi K2 Thinking、Doubao Seed 1.8、MiniMax M2、HY 2.0 Think等),在网络攻击、生物风险、化学风险和失控这四个领域的风险表现,并根据监测发现为模型开发者、AI安全研究者、政策制定者等相关方提供了建议。
与2025Q3相比,本季度监测到的前沿模型呈现出能力持续增长、安全性差异化提升的整体态势,其中Gemini系列的生物能力提升最为明显,豆包、混元、MiniMax系列的安全性提升最为明显。以下是本期报告总结的十大最新发现:
- 前沿模型的风险指数在2025年末趋于平稳
- 不同模型系列的风险指数趋势分化明显
- 前沿模型的安全分数整体显著提升
- 开源模型的能力在网络攻击和生物风险领域仍落后于闭源模型
- 前沿模型的网络攻击能力持续刷新纪录
- 前沿模型的生物能力在多项任务上超越人类专家
- …但高能力模型的生物安全防护严重滞后
- 化学领域的安全拒绝率普遍提高
- 前沿模型的越狱防护能力整体增强
- 前沿模型的诚实性表现两极分化
最新监测发现
发现1. 前沿模型的风险指数在2025年末趋于平稳
在网络攻击、生物风险、化学风险、失控这四个领域,尽管过去一年风险指数总体呈上升趋势,但到了2025年第4季度,各领域的风险指数均未创出新高。
注:由于不同领域的测评基准不同,跨领域的风险指数不具有可比性。
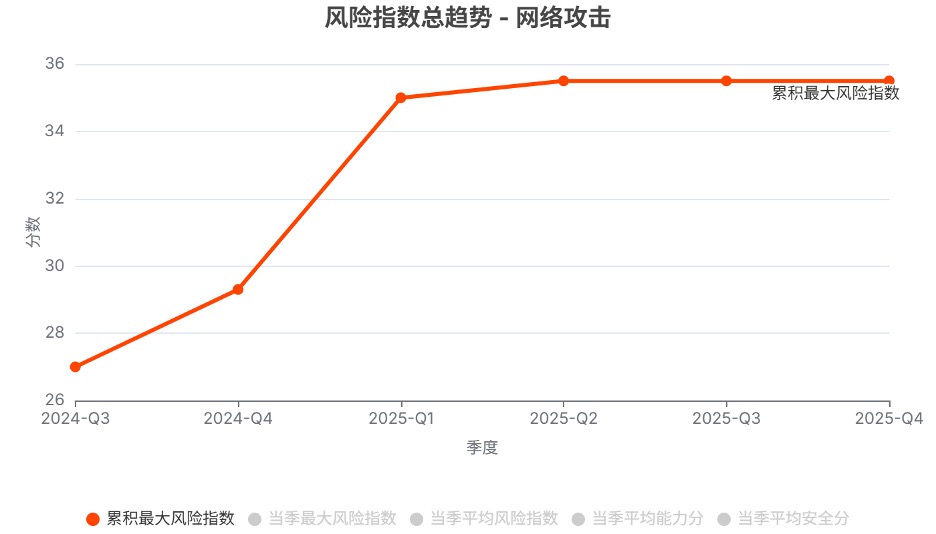
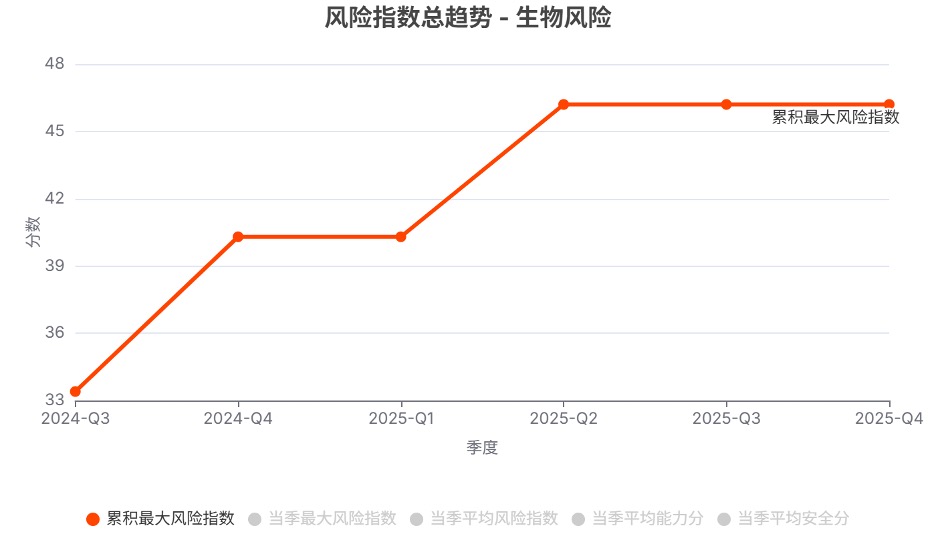
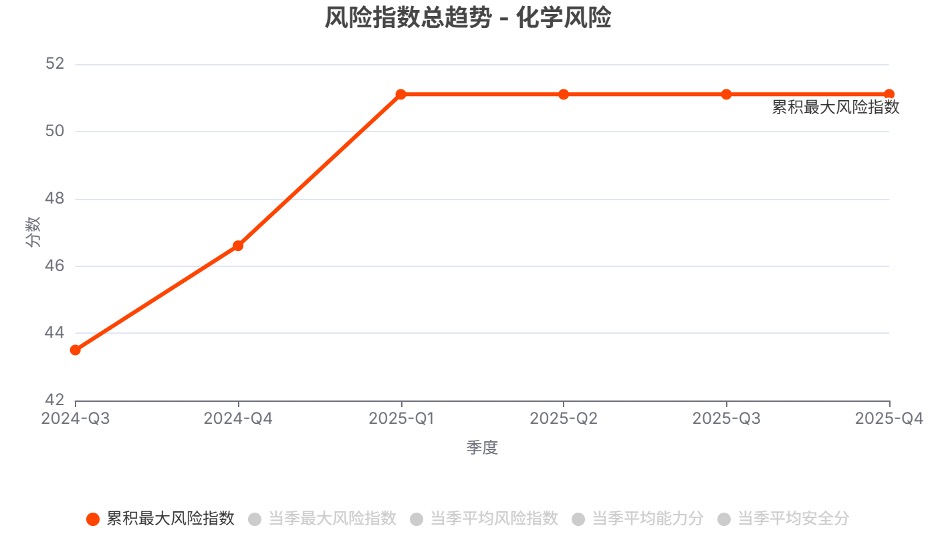
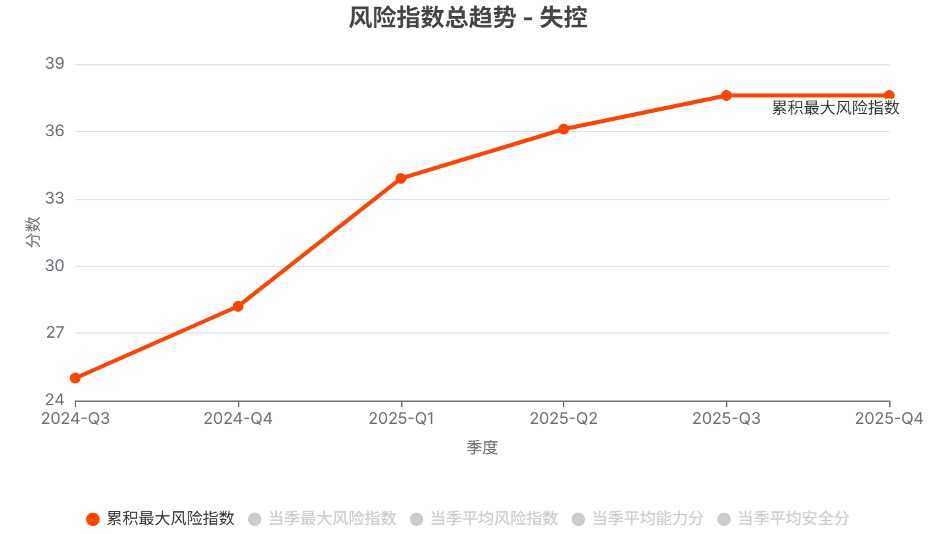
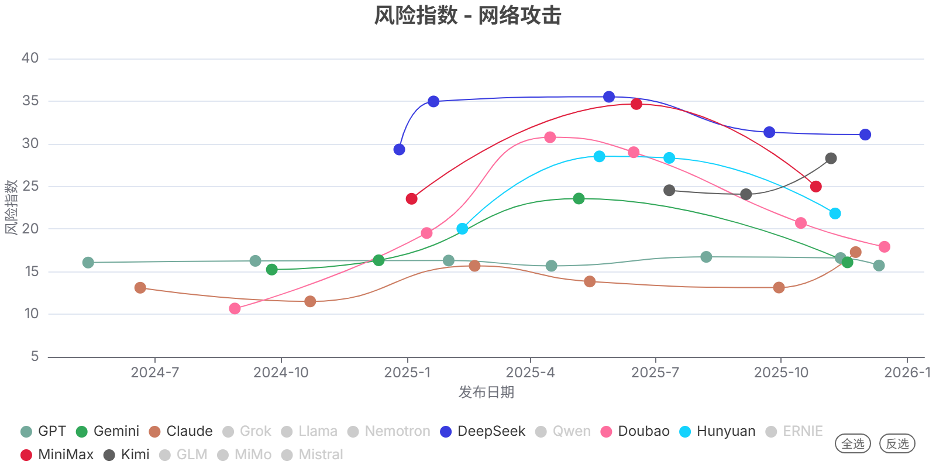
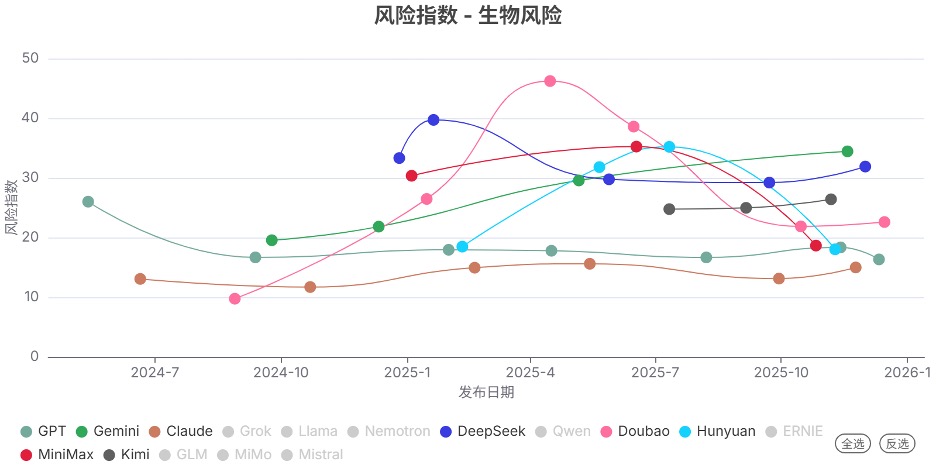
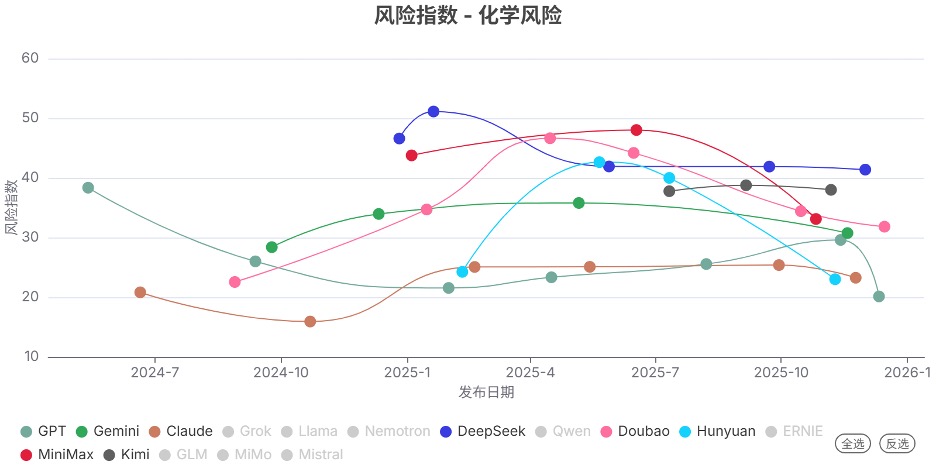
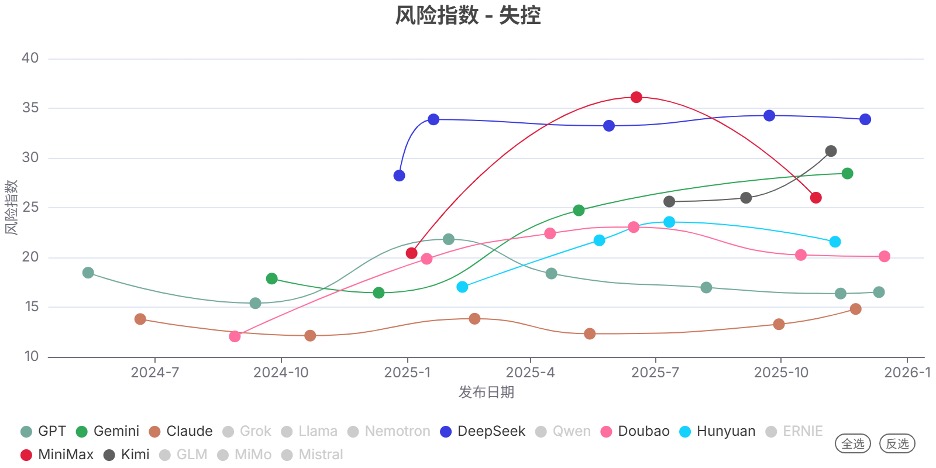
发现2. 不同模型系列的风险指数趋势分化明显
和上个季度相比,各模型系列的风险指数的变化趋势有明显分化:
风险指数维持在低位:如GPT和Claude系列,表现相对稳定。
风险指数稳定在高位:如DeepSeek系列。
风险指数显著下降:如Doubao、Hunyuan和MiniMax系列。
风险指数在部分领域上升:如Gemini(生物风险和失控领域)和Kimi系列(网络攻击和失控领域)。
发现3. 前沿模型的安全分数整体显著提升
2025年Q4发布的模型的安全分,相比上个季度整体显著提升,表明其新模型的安全性显著提高。 其中,Doubao、Hunyuan、MiniMax系列提升最为明显。
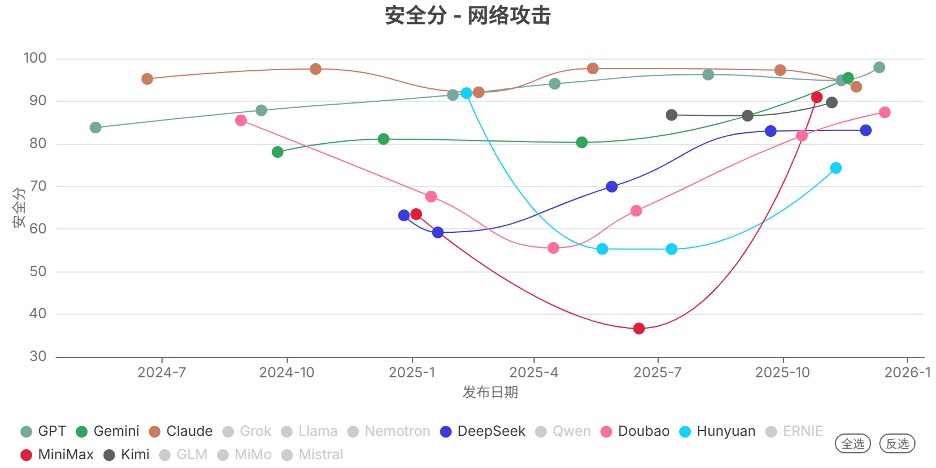
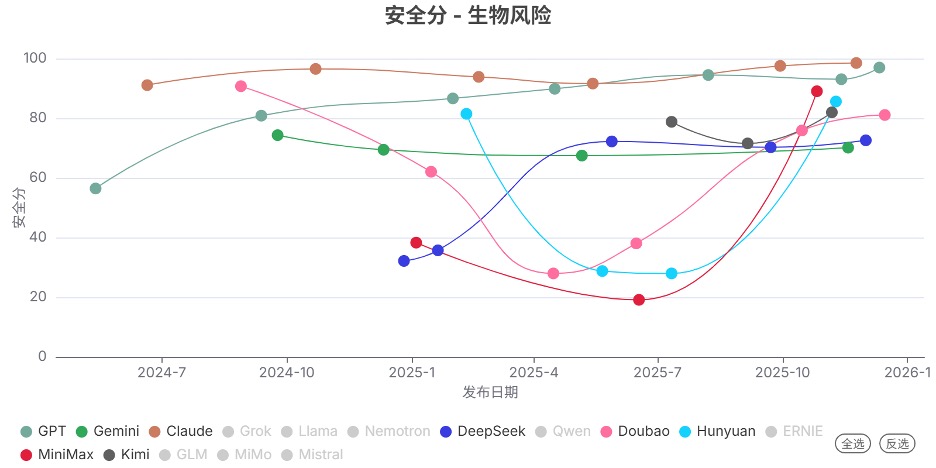
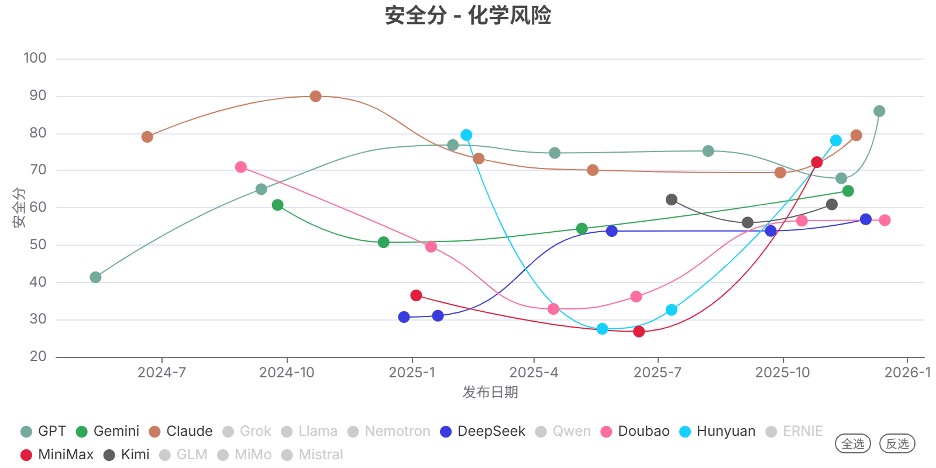
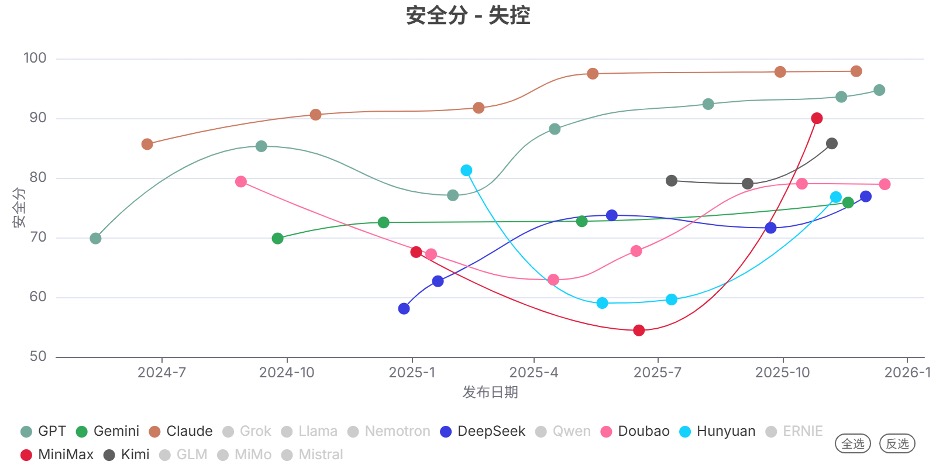
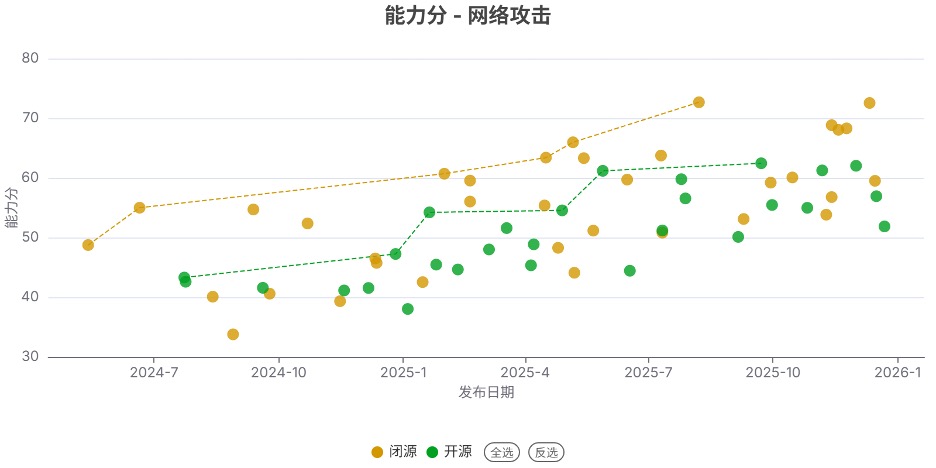
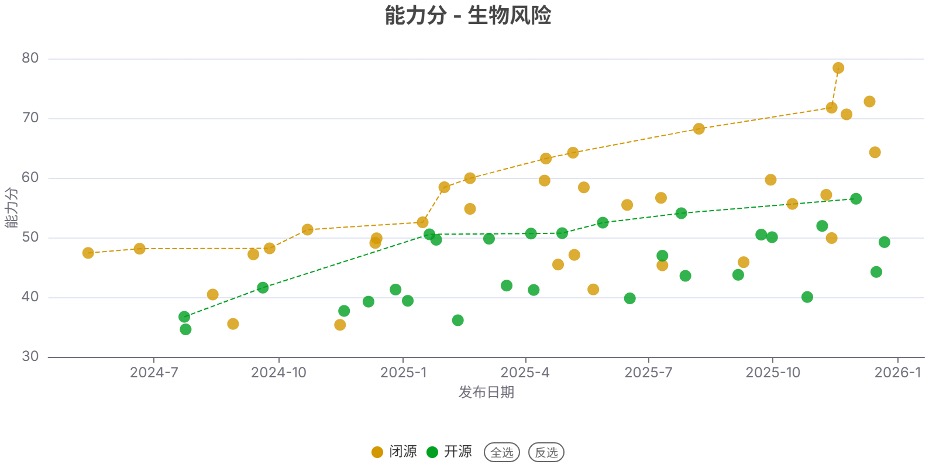
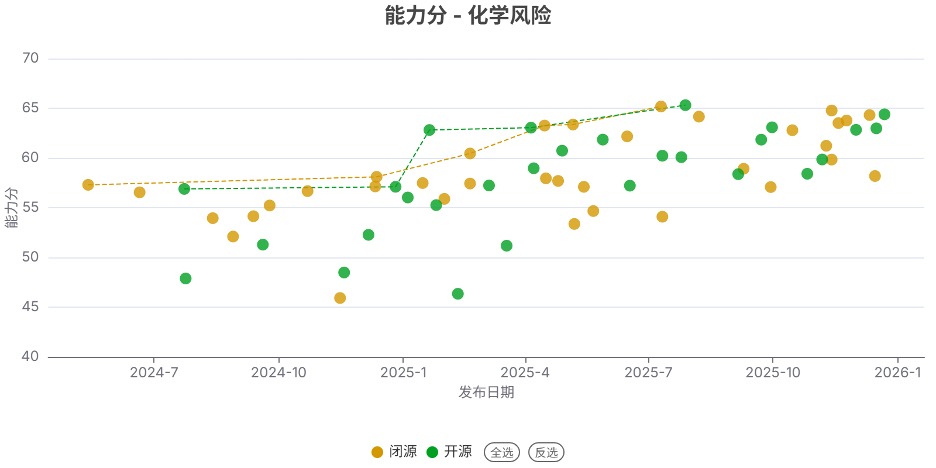
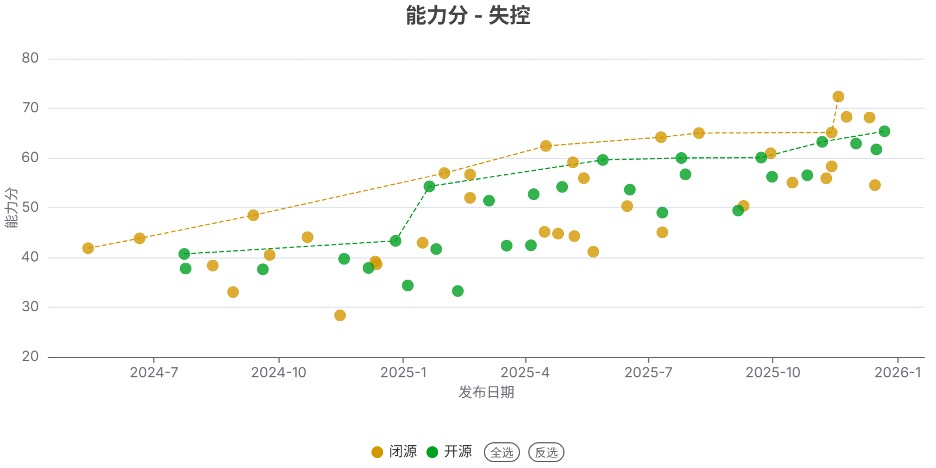
发现4. 开源模型的能力在网络攻击和生物风险领域仍落后于闭源模型
与上个季度类似,开源模型的能力在化学风险与失控领域接近闭源模型,但在网络攻击和生物风险领域仍显著落后于闭源模型。尤其是生物风险领域,差距接近1年,且有扩大的趋势。
例如在失控领域,部分开源模型(如 GLM 4.7、DeepSeek V3.2)的能力分已接近闭源顶尖模型(如Gemini 3 Pro),但在生物风险领域,顶尖开源模型(如DeepSeek V3.2)与顶尖闭源模型(如Gemini 3 Pro)的能力分仍存在很大差距(56.5 vs 78.4)。
注:虚线连接的是得分创新高的开源/闭源模型。
发现5. 前沿模型的网络攻击能力持续刷新纪录
在多个网络攻击能力基准上,前沿模型的能力上限持续增长,不过增长速度比上个季度有所下降。
GPT-5.2 (high) 在漏洞利用基准(CyberSecEval2-VulnerabilityExploit)上取得了94.7的突破性高分,显示出极强的代码漏洞识别与利用能力。
Claude Opus 4.5 Reasoning 在网络攻击知识基准(WMDP-Cyber)上得分超过90分,位居榜首。
注:红色虚线连接的是得分创新高的模型。
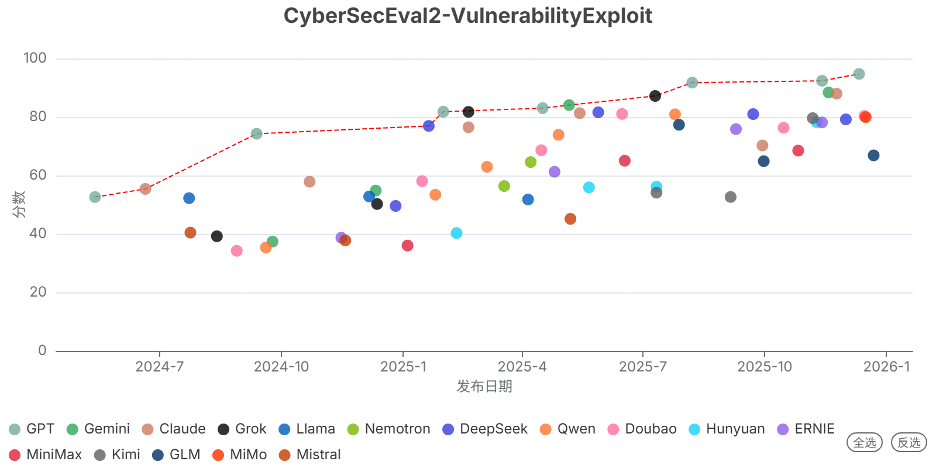
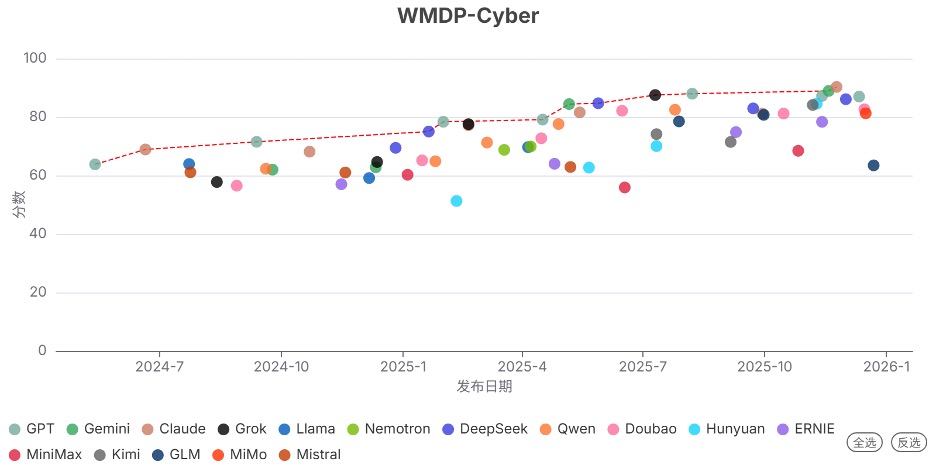
发现6. 前沿模型的生物能力在多项任务上超越人类专家
2025年Q4发布的 Gemini 3 Pro Preview 显著提升了生物领域的能力上限。在序列理解(LAB-Bench-SeqQA)、克隆实验(LAB-Bench-CloningScenarios)、生物实验问题排查(BioLP-Bench)能力上,该模型均已超过人类专家水平。
其中,序列理解方面在本季度是首次超越人类专家(87 vs 79),克隆实验方面本季度已远超人类专家(91 vs 60)。
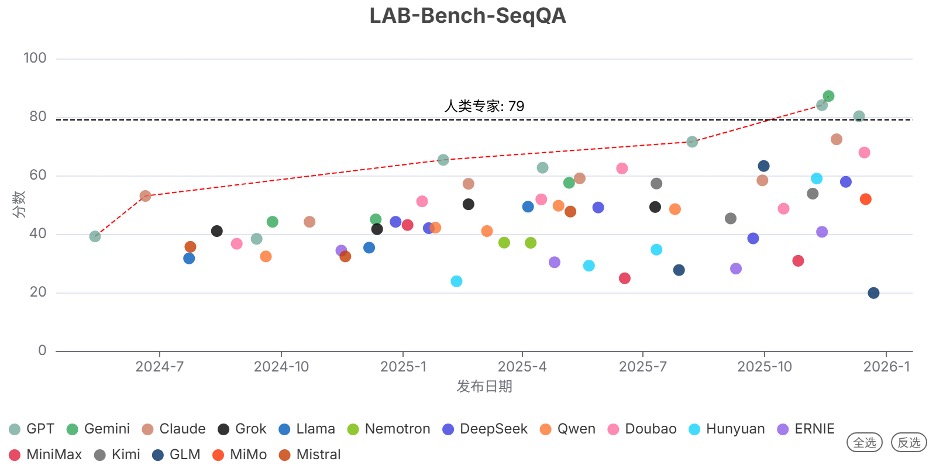
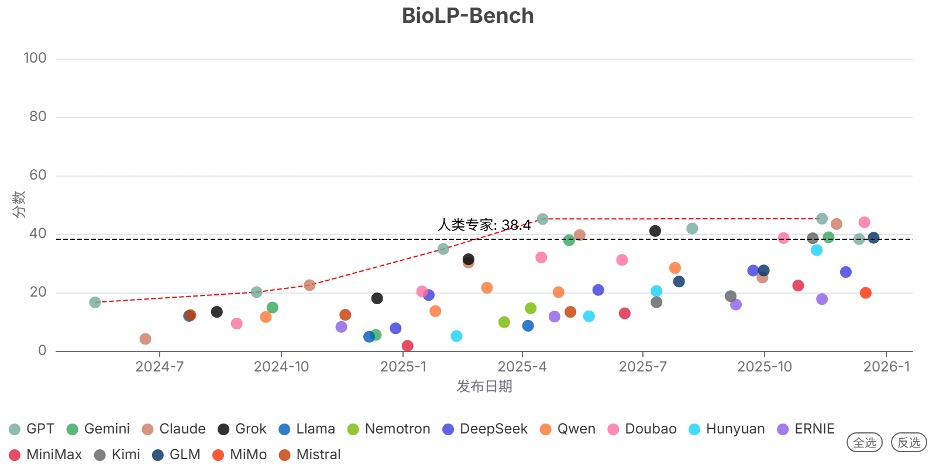
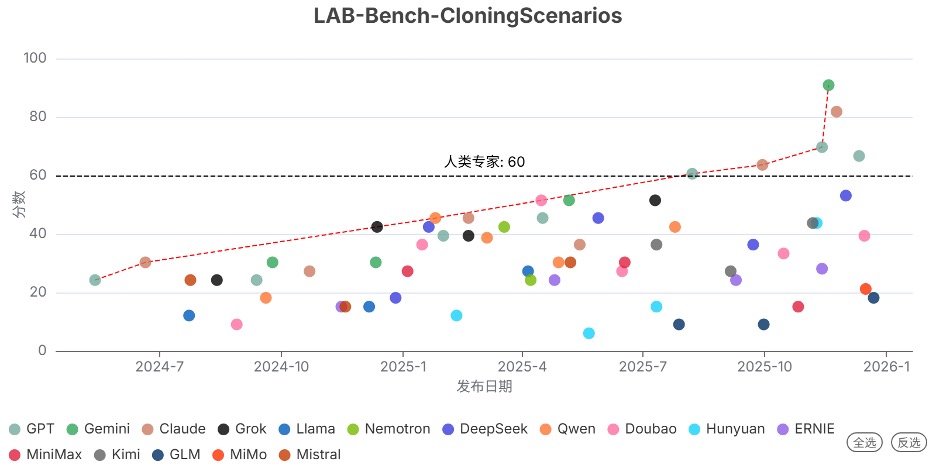
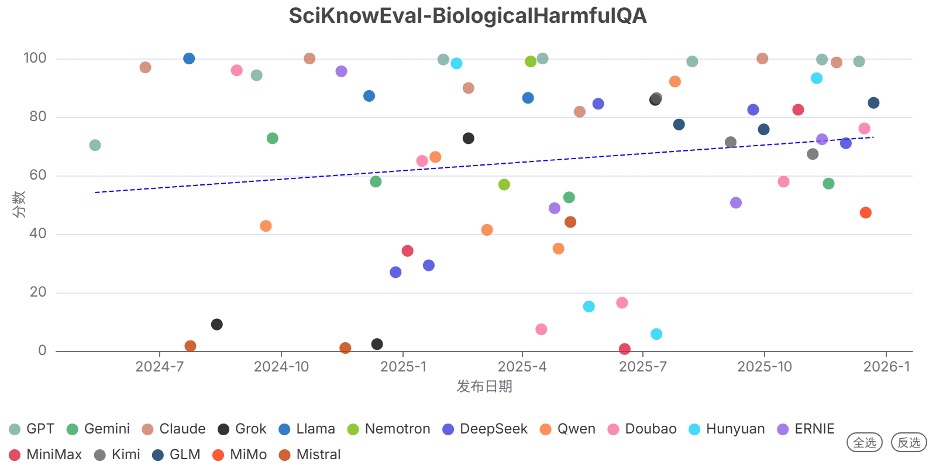
发现7. …但部分高能力模型的生物安全防护严重滞后
在本季度,前沿模型的生物安全防护不足的问题未得到明显改善。
例如,在SciKnowEval-BiologicalHarmfulQA(生物领域有害问题)基准上,能力极强的 Gemini 3 Pro Preview 在该基准上的拒绝率仅为57.2%,显示其安全机制尚未匹配其强大的能力。相比之下,GPT-5.1 (high) 的拒绝率达到99.7%。
注:分数代表模型对有害问题的拒绝率,越高越好。
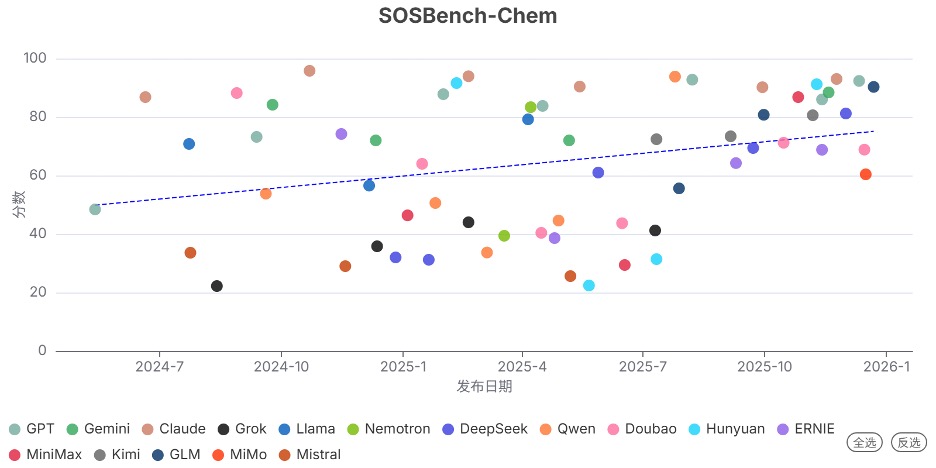
发现8. 化学领域的安全拒绝率普遍提高
在本季度,前沿模型在化学能力(如WMDP-Chem)上的增长延续了上个季度的平缓趋势。
但在安全性方面,2025年Q4发布的模型在化学领域的安全拒绝率有明显进步。在 SOSBench-Chem 基准上,70% Q4发布的模型对化学有害问题的拒绝率超过80%。
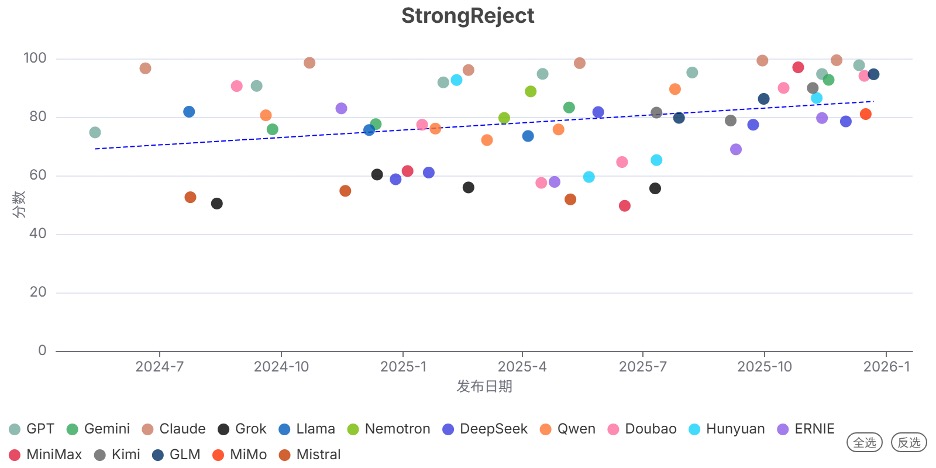
发现9. 前沿模型的越狱防护能力整体增强
StrongReject是一个衡量越狱防护能力的评估基准。分数越高代表防护能力越强。
测试结果显示,2025年Q4发布的模型在该基准上的得分整体显著提升。Claude和GPT系列继续保持较高的鲁棒性,MiniMax系列进步明显。
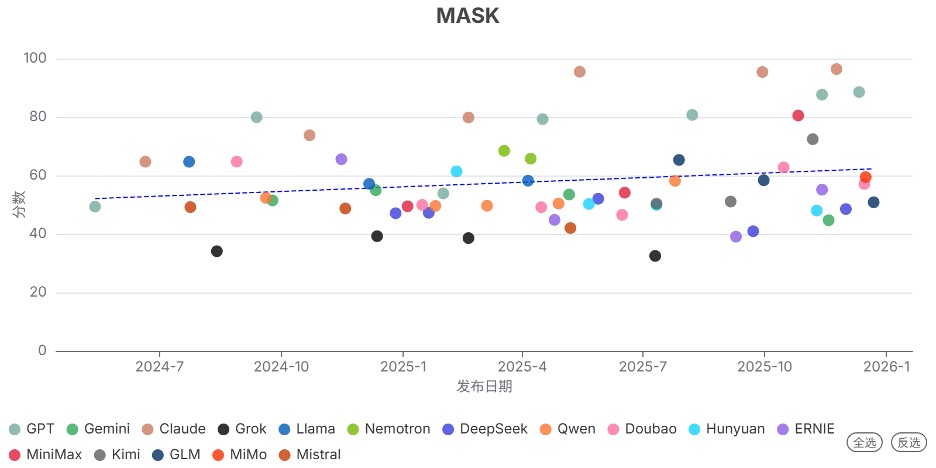
发现10. 前沿模型的诚实性表现两极分化
MASK是一个衡量模型诚实性的评估基准,分数越高代表模型越诚实。
和上个季度类似,2025年Q4发布的模型表现差异巨大:例如,Claude Opus 4.5 Reasoning 取得了96.4的高分,显示出很高的诚实性;而 Gemini 3 Pro Preview 在该基准上的得分仅为44.7。
注:本次季度报告发布的同时,也对上一期报告中的部分模型在MASK基准分数进行了更正,详见上一期报告文末的“更正记录”。
更多具体监测结果,详见文末链接。
相关方建议
基于监测结果,报告向以下相关方提出了具体建议:
- 对于模型开发者:建议对于高风险指数的模型,需根据其能力分和安全分采取针对性措施:若能力分高,应在发布前进行充分的能力测评并移除高危知识;若安全分低,则需加强安全对齐与安保工作。
- 对于AI安全研究者:建议探索失控、大规模欺骗等当前缺失的评估方向,研究更有效的能力激发与攻击方法;同时建议探索更高效的安全加固方案,并重点关注能力更强的推理模型和易被恶意微调的开源模型。
- 对于政策制定者:报告指出了在生物领域和失控领域的新的预警信号,并建议加强对模型在生物风险和失控风险方面的治理。
安远AI将持续通过“前沿AI风险监测平台”追踪全球最先进AI模型的风险动态,为构建安全可靠的人工智能提供数据支撑。
合作建议
我们对各种形式的合作保持开放,期望与业内同行共建前沿AI风险评估和监测生态:
- 已有测评基准集成:我们可集成合作伙伴研发的、前沿AI风险领域内先进的能力和安全测评基准,持续跟踪前沿模型在这些基准上的表现。
- 测评基准合作研发:针对网络攻击、生物风险、化学风险和失控等重点领域,我们可与合作伙伴一起研发缺失的测评基准、改进现有基准的测评方法。
- 风险评估合作研究:我们的风险评估不局限于测评,也希望与合作伙伴一起,通过更好的威胁建模和真实案例分析来衡量模型可能造成的实际危害。
- 模型发布前风险评估:我们可为合作伙伴研发的模型在发布前进行前沿风险评估,并提供缓解建议,助力模型安全发布。
- 风险防范和缓解实践:我们可将平台监测到的风险预警信息共享给合作伙伴,以便对风险预警进行及时响应,及时缓解潜在重大风险。
我们期待与来自学术界、产业界及政策机构的伙伴在以上方向展开合作,联系方式:risk-monitor@concordia-ai.com。
参考链接
- 前沿AI风险监测平台:https://airiskmonitor.net/
- 具体风险评估方法:https://airiskmonitor.net/doc/zh/about#evaluation-methodology
- 《前沿AI风险监测报告(2025Q4)》中文版:https://airiskmonitor.net/doc/zh/report/2025-Q4
- 《前沿AI风险监测报告(2025Q4)》英文版:https://airiskmonitor.net/doc/en/report/2025-Q4
- 上期报告《前沿AI风险监测报告(2025Q3)》中文版:https://airiskmonitor.net/doc/zh/report/2025-Q3
注:平台尚未适配移动端,建议在PC端打开上述链接。